Semi-Supervised Few-Shot Learning with Prototypical Random Walks
AAAI 2021 MetaLern Workshop Oral
- Ahmed Ayyad Technical University Munich
- Yuchen Li KAUST
- Raden Muaz KAUST
- Shadi Albarqouni TU Munich | Helmholtz AI
- Mohamed Elhoseiny KAUST
Abstract
Recent progress has shown that few-shot learning can be improved with access to unlabelled data, known as semi-supervised few-shot learning (SS-FSL). We introduce an SS-FSL approach, dubbed as Prototypical Random Walk Networks (PRWN), built on top of Prototypical Networks (PN). We develop a random walk semi-supervised loss that enables the network to learn representations that are compact and well-separated. Our work is related to the very recent development on graph-based approaches for few-shot learning. However, we show that compact and well-separated class representations can be achieved by modeling our prototypical random walk notion without needing additional graph-NN parameters or requiring a transductive setting where a collective test set is provided. Our model outperforms prior art in most benchmarks with significant improvements in some cases. Our model, trained with 40 % of the data as labeled, compares competitively against fully supervised prototypical networks, trained on 100 % of the labels, even outperforming it in the 1-shot mini-Imagenet case with 50.89 % to 49.4 % accuracy. We also show that our model is resistant to distractors, unlabeled data that does not belong to any of the training classes, and hence reflecting robustness to labeled / unlabelled class distribution mismatch.
Toy Example
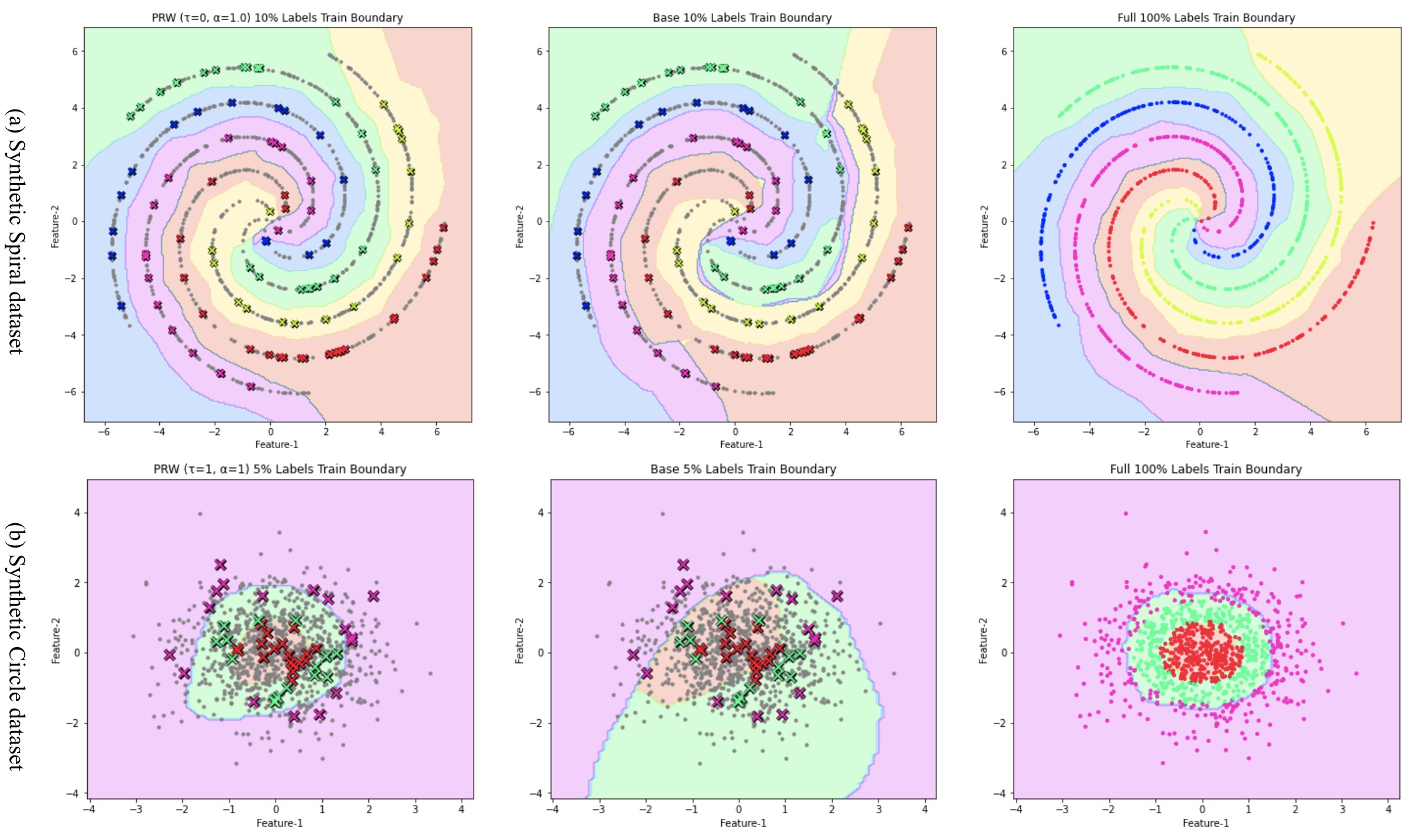
Above Figure shows the results, it can be seen that the proposed method can “connect the dots” of unlabeled points in green region and purple region, hence producing decision boundary similar to 100% labels. In Gaussian circle dataset, random walk loss helps the model fits the circle more in just few epochs, but the model without random walk loss still has many mis-classified points and the circular outline is not obvious.
Dataset
- Omniglot is a dataset contains 1,623 different handwritten characters from 50 different letters. Each character was drawn online by 20 different people using Amazon's Mechanical Turk.
You can download Omniglot here (9.3MB) - miniImageNet contains 60,000 color pictures in 100 categories, each of which has 600 samples, and the size of each picture is 84×84. Generally speaking, the categories of training set and test set of this data set are divided into 80:20. Compared with the CIFAR10 data set, the miniImageNet data set is more complex, but it is more suitable for prototyping and experimental research.
You can download miniImageNet here (1.1GB) - tieredImageNet is a small sample classification task data set. Like miniImagenet, it is a subset of ILSVRC-12. However, tieredImageNet represents a larger subset of ILSVRC-12 (608 classes compared to 100 classes for miniImageNet). Similar to Omniglot, which groups characters into letters, tieredImageNet divides the categories into broader categories corresponding to higher-level nodes in the ImageNet hierarchy. There are 34 categories (category), each category contains 10 to 30 categories (class). These are divided into 20 training, 6 validation and 8 test categories.
You can download tieredImageNet here (12.9GB)
Methodology: Prototypical Random Walks

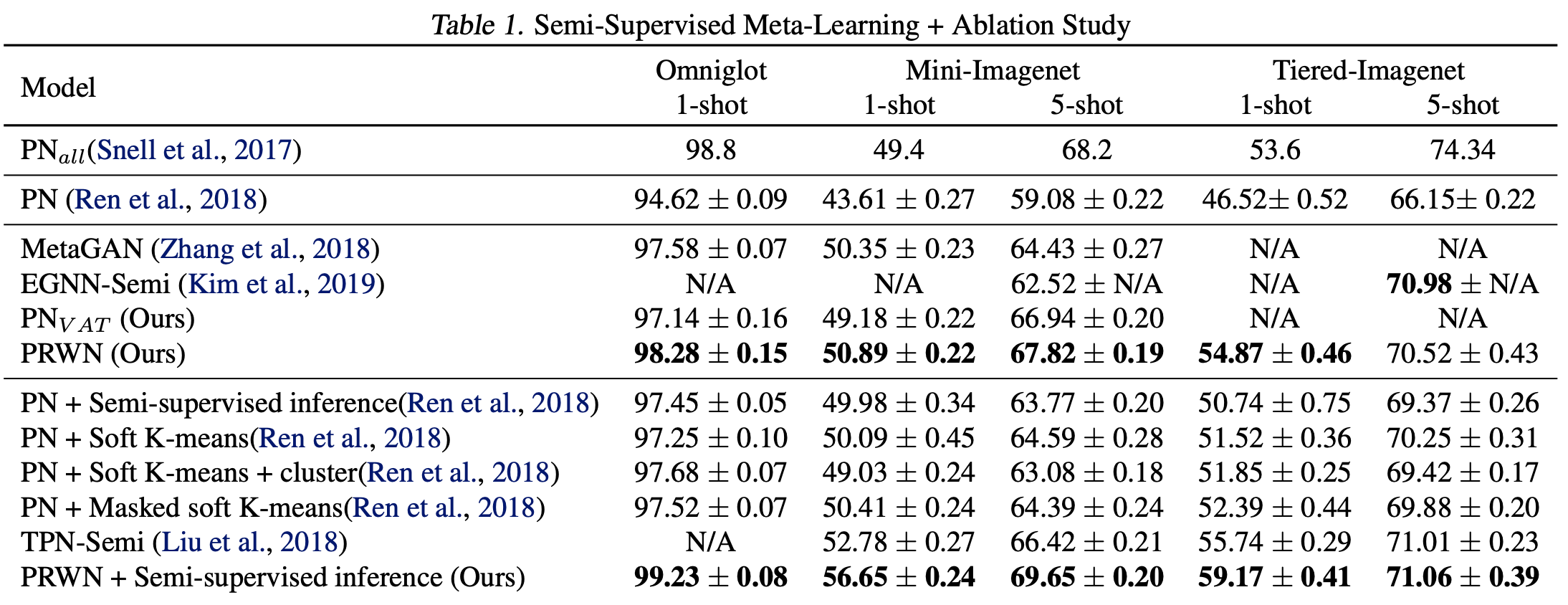
Qualitative Results
Citation
If you find our work useful in your research, please consider citing:
@article{Ahmed2020prw,
title={Semi-Supervised Few-Shot Learning with Prototypical Random Walks},
author={Ayyad, Ahmed and Li, Yuchen and Muaz, Raden and Albarqouni, Shadi and Elhoseiny, Mohamed},
journal={35th AAAI Conference on Artificial Intelligence (AAAI)},
year={2021}
}